Describe features of transactional workloads
Transactional workloads play a critical role in ensuring the smooth operation of businesses and maintaining data integrity. These workloads encompass activities such as capturing customer orders, processing financial transactions, and updating inventory levels.
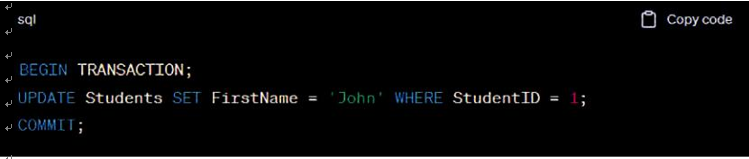
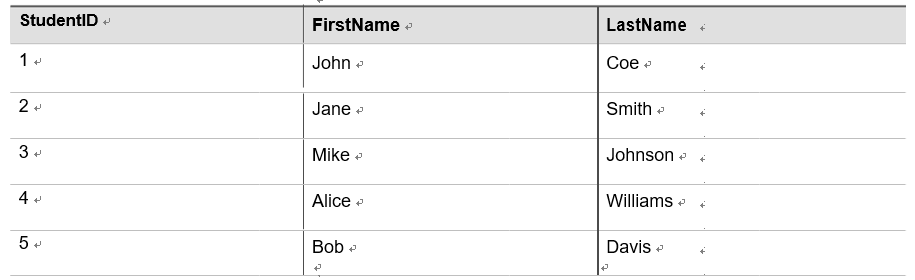
Transactional workloads are designed to handle business operations that involve data modifications, ensuring the accuracy, consistency, and reliability of data. Let’s consider an e-commerce platform that processes customer orders. Each customer order represents a trans-action that requires capturing the order details, updating inventory levels, and recording the financial transaction. These transactions must be executed reliably and in an atomic manner, meaning they should either complete successfully or be rolled back entirely if an error occurs.
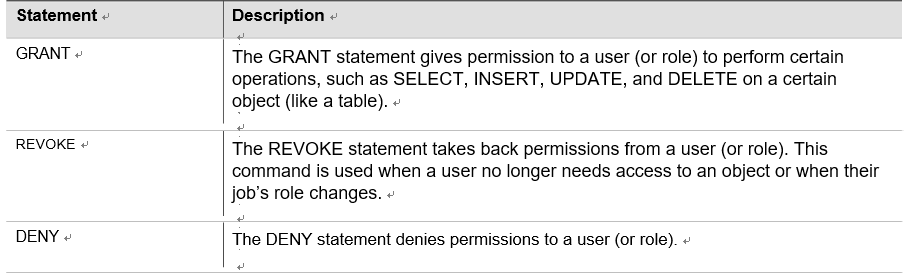
Transactional workloads offer several advantages for business. First, they ensure data con-sistency and integrity. The ACID properties guide transactional processing, ensuring that data remains in a consistent state even in the event of failure or concurrent access. This integrity is crucial for financial systems, inventory management, and other critical business functions.
Second, transactional workloads support concurrency control and isolation in a multiuser environment, where multiple transactions can occur simultaneously. Transactional processing mechanisms ensure that transactions are executed independently and do not interfere with each other, maintaining data integrity and preventing conflicts.
Furthermore, transactional workloads facilitate data durability and reliability. Transactional systems employ techniques such as write-ahead logging and database recovery mechanisms to ensure that committed transactions persist even in the face of system failures. This durability ensures that critical business operations can be restored and recovered without data loss.
Transactional workloads are supported by various database systems such as relational databases, where ACID properties are typically enforced. These systems provide transac-tion management features that guarantee data consistency, durability, and isolation. We can say transactional workloads are essential for maintaining accurate data, supporting reliable business operations, and ensuring data integrity. By executing operations in an atomic and consistent manner, businesses can confidently process customer orders, handle financial trans-actions, and manage inventory levels, fostering trust and reliability in their operations.